使用TokuMX配置Replica Set集群
清泛原创
TokuTek公司出品的TokuDB,其主要特色是在拥有完整事务处理能力的前提下,实现了大幅度的数据压缩,并有着良好的性能 表现。TokuTek的工程师再接再厉,把目前非常流行的NoSQL数据库MongoDB的底层替换成与TokuDB同样的存储引擎,达到了非常好的效果。
MongoDB拥有灵活的文档型数据结构和方便的操作语法,在新兴的互联网应用中得到了广泛的部署,但对于其底层的存储引擎,我一直有一些保留意 见。据我了解,其采用了MMAP的方式来操作数据文件,这就导致我们无法限制MongoDB进程所使用的内存容量,目前最好的部署办法就只能是将其单独部 署在一台服务器上。另外,MongoDB也不能严格的支持事务,对于并发写入的锁的粒度也非常粗。
TokuMX的出现解决了这一切,它为MongoDB替换了一颗真正的数据库存储引擎,我们现在可以像使用MySQL数据库一样精确的指定TokuMX最大可用内存,它也完整支持的事务处理。当然了,TokuTek引以为傲的数据压缩能力也是一点也没落下。性能详细对比请参见《TokuMX vs. MongoDB 性能对比》。
下载地址:http://www.tokutek.com/tokumx-for-mongodb/TokuMX目前只有Linux版本,下载完成后
解压(tar -zxvf xxxx.tar.gz)
进入bin目录,新建配置文件如:tokumx.conf (文件名随意)
内容如下:
logpath=/home/apps/tokumx/logs/tokumx.log
cacheSize=10G
oplogSize=10240
fork = true
port = 27017
dbpath=/home/apps/tokumx/data
replSet=ReplSetName
expireOplogDays=14
./mongod -f tokumx.conf 启动,可使用客户端工具MongoVUE连接访问。以下介绍TokuMX 集群的配置方法(MongoDB同样适用):
Replica Set是TokuMX 典型的集群部署方式,其特点是:
1、集群由多个TokuMX 实例构成。
2、多个实例中,只有一个实例是Primary角色,其他都是Secondary角色。
3、默认情况下,只有Primary实例可读可写,Secondary角色不可读写。
4、可以手工配置Secondary实例使之可读。
5、当Primay实例宕机后,其余的实例会尝试选举出一个新的实例作为Primary
6、TokuMX 的客户端会自动发现集群的所有成员,并且会自动识别Primary实例。
使用TokuMX配置Replica Set过程很简单,我们有如下基础环境:
服务器信息:IP地址:172.16.88.97,
我们准备为此Replica Set启动三个TokuMX实例,
端口分别为:27017,27018,27019.
三个实例的配置文件为:
实例1:
logpath=/data/mongod/mongod.log
fork = true
port = 27017
dbpath=/data/mongod
cacheSize=2G
replSet=ReplSetName
expireOplogDays=14
实例2:
logpath=/data/mongod2/mongod.log
fork = true
port = 27018
dbpath=/data/mongod2
cacheSize=2G
replSet=ReplSetName
expireOplogDays=14
实例3:
logpath=/data/mongod3/mongod.log
fork = true
port = 27019
dbpath=/data/mongod3
cacheSize=2G
replSet=ReplSetName
expireOplogDays=14
然后我们启动三个实例:
mongod -f r1.conf
mongod -f r2.conf
mongod -f r2.conf
然后使用mongo客户端连接r1实例(实际上任意节点都行)进行配置:(连接方法:进入bin目录,执行./mongo或mongo.exe,可加参数指定ip、端口,默认本机27017)
config={
"_id" : "ReplSetName",
"members" : [
{"_id" : 0, "host" : "172.16.88.97:27017",priority:2},
{"_id" : 1, "host" : "172.16.88.97:27018",priority:1},
{"_id" : 2, "host" : "172.16.88.97:27019",arbiterOnly : true}
]
}
# 建议先执行上面配置,然后执行初始化
rs.initiate(config)
"ReplSetName"即集群的名字,任意都行,arbiterOnly是仲裁节点(仲裁节点不存储数据,只是负责故障转移的群体投票),然后查看集群运行情况(任意节点都可查看,结果都一样):rs.status()
我们发现,单个节点执行以上配置完成后,它会自动关联配置中的其他节点,形成一个集群。
跨不同服务器的集群配置与上面的步骤一样,以下是一些结果截图:
注意:初始化配置只能在集群中一个实例上进行操作。如果我们是将一个有数据的单独实例升级为Replica Set,那么就在有数据的实例上执行初始化操作就可以了,集群的其他实例会自动将数据同步过去。

> rs.initiate(config)
{
"ok" : 0,
"errmsg" : "couldn't initiate : need all members up to initiate, not ok : 172.17.39.149:27017"
}
需要在防火墙配置中打开相应端口:vi /etc/sysconfig/iptables
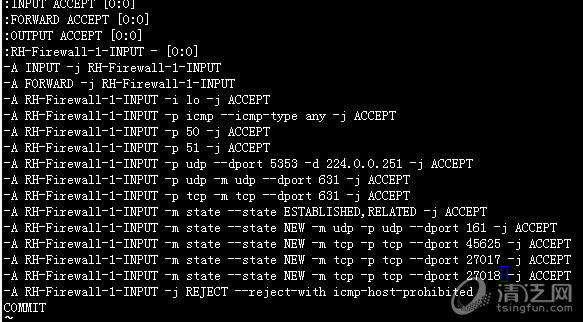
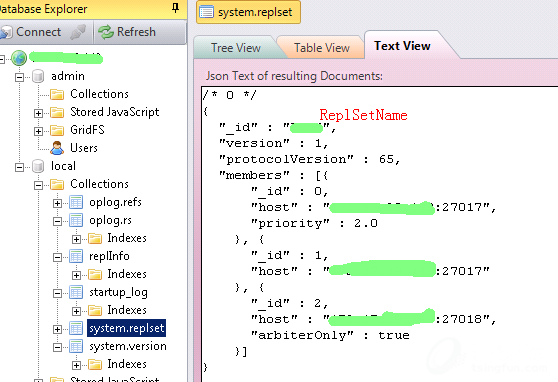
可以查看集群的详细信息:
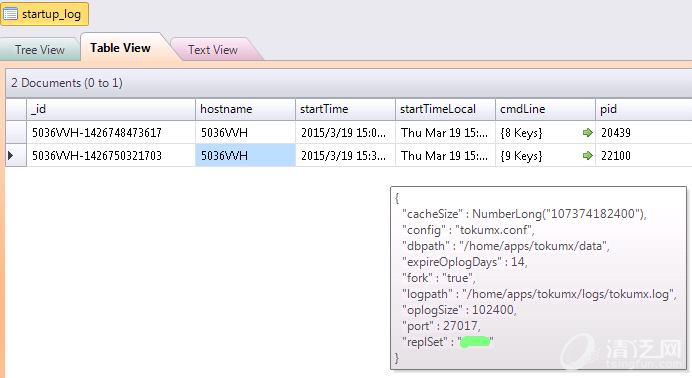
每次启动服务的记录:
可以发现,集群的关联配置不是写在.conf文件中(即.conf配置完全独立)的。任意节点临时执行一次集群配置初始化,最终的关联配置被存于Tokumx 的 system.replset表中,同步于所有节点(仲裁节点除外,它不存储、不同步数据)。
关闭Mongodb:
官方文档说明要使用 kill -15,killall mongod或者在client的shell里(./mongo),
use admin
db.shutdownServer()
有任何关于MongoDB/TokuMX方面的问题,欢迎回复评论。
上一篇:第一页
下一篇:MongoDB副本集详解 优于以往的主从模式
 评论加载中,请稍后...
评论加载中,请稍后...