一致性hash和solr千万级数据分布式搜索引擎中的应用
那怎么搭建一个好的系统架构呢?这个话题太大,这里主要说一下数据分流的方式。比如我们的数据库服务器只能存储200个数据,突然要搞一个活动预估达到600个数据。
可以采用两种方式:横向扩展或者纵向扩展。
纵向扩展是升级服务器的硬件资源。但是随着机器的性能配置越高,价格越高,这个代价对于一般的小公司是承担不起的。
横向扩展是采用多个廉价的机器提供服务。这样一个机器只能处理200个数据、3个机器就可以处理600个数据了,如果以后业务量增加还可以快速配置增加。在大多数情况都选择横向扩展的方式。如下图:

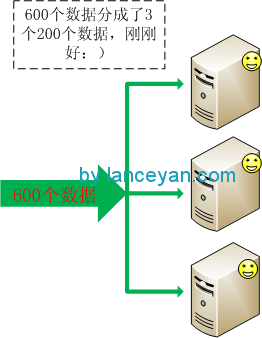
目前看起来是不是解决我们的问题了,所有数据都很好的分发并且没有达到系统的负载。但如果我们的数据需要存储、需要读取就没有这么容易了。业务增多怎么办,大家按照上面的横向扩展知道需要增加一台服务器。但是就是因为增加这一台服务器带来了一些问题。看下面这个例子,一共9个数,需要放到2台机器(1、2)上。各个机器存放为:1号机器存放1、3、5、7、9 ,2号机器存放 2、4、6、8。如果扩展一台机器3如何,数据就要发生大迁移,1号机器存放1、4、7, 2号机器存放2、5、8, 3号机器存放3、6、9。如图:
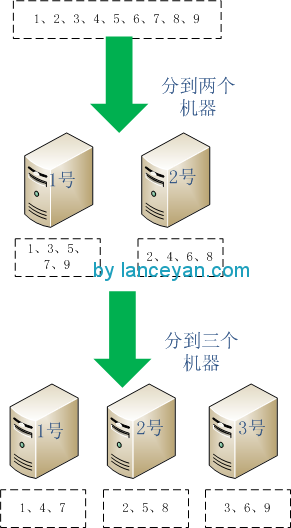
从图中可以看出 1号机器的3、5、9迁移出去了、2好机器的4、6迁移出去了,按照新的秩序再重新分配了一遍。数据量小的话重新分配一遍代价并不大,但如果我们拥有上亿、上T级的数据这个操作成本是相当的高,少则几个小时多则数天。并且迁移的时候原数据库机器负载比较高,那大家就有疑问了,是不是这种水平扩展的架构方式不太合理?
一致性hash就是在这种应用背景提出来的,现在被广泛应用于分布式缓存,比如memcached。下面简单介绍下一致性hash的基本原理。最早的版本 http://dl.acm.org/citation.cfm?id=258660。国内网上有很多文章都写的比较好。如: http://blog.csdn.net/x15594/article/details/6270242
准备:1、2、3 三台机器
还有待分配的9个数 1、2、3、4、5、6、7、8、9
一致性hash算法架构
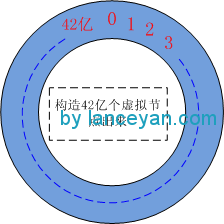
二、将三台机器分别取IP进行hashcode计算(这里也可以取hostname,只要能够唯一区别各个机器就可以了),然后映射到2的32次方上去。比如1号机器算出来的hashcode并且mod (2^32)为 123(这个是虚构的),2号机器算出来的值为 2300420,3号机器算出来为 90203920。这样三台机器就映射到了这个虚拟的42亿环形结构的节点上了。

三、将数据(1-9)也用同样的方法算出hashcode并对42亿取模将其配置到环形节点上。假设这几个节点算出来的值为 1:10,2:23564,3:57,4:6984,5:5689632,6:86546845,7:122,8:3300689,9:135468。可以看出 1、3、7小于123, 2、4、9 小于 2300420 大于 123, 5、6、8 大于 2300420 小于90203920。从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个Cache节点上。如果超过2^32仍然找不到Cache节点,就会保存到第一个Cache节点上。也就是1、3、7将分配到1号机器,2、4、9将分配到2号机器,5、6、8将分配到3号机器。

这个时候大家可能会问,我到现在没有看见一致性hash带来任何好处,比传统的取模还增加了复杂度。现在马上来做一些关键性的处理,比如我们增加一台机器。按照原来我们需要把所有的数据重新分配到四台机器。一致性hash怎么做呢?现在4号机器加进来,他的hash值算出来取模后是12302012。 5、8 大于2300420 小于12302012 ,6 大于 12302012 小于90203920 。这样调整的只是把5、8从3号机器删除,4号机器中加入 5、8。

同理,删除机器怎么做呢,假设2号机器挂掉,受影响的也只是2号机器上的数据被迁移到离它节点,上图为4号机器。

大家应该明白一致性hash的基本原理了吧。不过这种算法还是有缺陷,比如在机器节点比较少、数据量大的时候,数据的分布可能不是很均衡,就会导致其中一台服务器的数据比其他机器多很多。为了解决这个问题,需要引入虚拟服务器节点的机制。如我们一共有只有三台机器,1、2、3。但是实际又不可能有这么多机器怎么解决呢?把 这些机器各自虚拟化出来3台机器,也就是 1a 1b 1c 2a 2b 2c 3a 3b 3c,这样就变成了9台机器。实际 1a 1b 1c 还是对应1。但是实际分布到环形节点就变成了9台机器。数据分布也就能够更分散一点。如图:


建立和更新需要维持机器的位置,能够根据数据的key找到对应的数据分发并更新。这里需要考虑的是如何高效、可靠的把数据建立、更新到索引里。
备份服务器防止建立服务器挂掉,可以根据备份服务器快速恢复。
读服务器主要做读写分离使用,防止写索引影响查询数据。
集群管理服务器管理整个集群内的服务器状态、告警。
扩展阅读:
java的hashmap随着数据量的增加也会出现map调整的问题,必要的时候就初始化足够大的size以防止容量不足对已有数据进行重新hash计算。
语言实现:
http://weblogs.java.net/blog/2007/11/27/consistent-hashing java 版本的例子
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx PHP 版的例子
http://www.codeproject.com/KB/recipes/lib-conhash.aspx C语言版本例子
原创文章,转载请注明: 转载自LANCEYAN.COM
上一篇:分布式系统的事务处理
下一篇:一文了解大数据领域创业的机会与方向
 评论加载中,请稍后...
评论加载中,请稍后...