libevent对比libev的基准测试
本文档简要描述了针对 libevent 和 libev 运行 libevent 基准程序的结果。
Libevent 概述
Libevent(于 2000-11-14 首次发布)是一个高性能事件循环,支持简单的 API、两种事件类型(可以是 I/O+超时或信号+超时)和多个“后端”(在撰写本文时选择、轮询、epoll、kqueue 和 /dev/poll)。
在算法上,它使用红黑树来组织计时器和其他类型的双向链表。每个文件描述符或信号最多可以有一个读取和一个写入观察者。它还提供了一个简单的 DNS 解析器和服务器以及 HTTP 服务器和客户端代码,以及一个套接字缓冲抽象。
Libev 概览
Libev(2007-11-12 首次发布)也是一个高性能的事件循环,支持八种事件类型(I/O、实时定时器、挂钟定时器、信号、子状态变化、空闲、检查和准备处理程序) .
它使用优先级队列来管理计时器并使用数组作为基本数据结构。它对等待同一事件的观察者数量没有人为限制。它为 libevent 和可选的相同 DNS、HTTP 和缓冲区管理提供了一个仿真层(通过其仿真层重用相应的 libevent 代码)。
基准设置
基准测试非常简单:首先创建多个套接字对,然后安装这些对的事件观察器,然后(较少)数量的“活动客户端”在这些套接字的子集上发送和接收数据。
使用的基准程序是bench.c,取自 libevent 发行版,经过修改以收集每次测试迭代的总时间,可选择启用事件观察器的超时以及可选择使用本机 libev API 并以不同方式输出时间。
对于 libevent,使用版本 1.4.3,而对于 libev,使用版本 3.31。库和测试程序均由带有优化选项的 gcc 4.2.3 版编译,-O3 -fno-guess-branch-probability -g并在带有 Debian GNU/Linux(Linux 版本 2.6.24-1)的 3.6GHz Core2 Quad 上运行。两个库都配置为使用 epoll 接口(测试机器上任一库中可用的性能最高的接口)。
使用相同的基准程序来运行 libevent 与 libevent 仿真基准测试(在这种情况下执行相同的代码路径/源代码行)并运行本机 libev API 基准测试(具有不同的代码路径,但功能相同)。
libevent 和 libev+libevent 仿真版本之间的差异严格限于使用不同的头文件(libevent 中的 event.h,或 libev 中的 event.h 仿真)。
基准程序的每次运行由两次迭代组成,输出每次迭代的总时间以及仅用于处理请求的时间。该程序针对各种文件描述符总数运行。每次运行由六个单独的运行组成,使用的结果是这些运行的最短时间,用于测试的第二次迭代。
测试程序在自己的 CPU 上运行,具有实时优先级,以实现稳定的计时。
第一个基准:没有超时,100 和 1000 个活动客户端
事不宜迟,以下是结果:
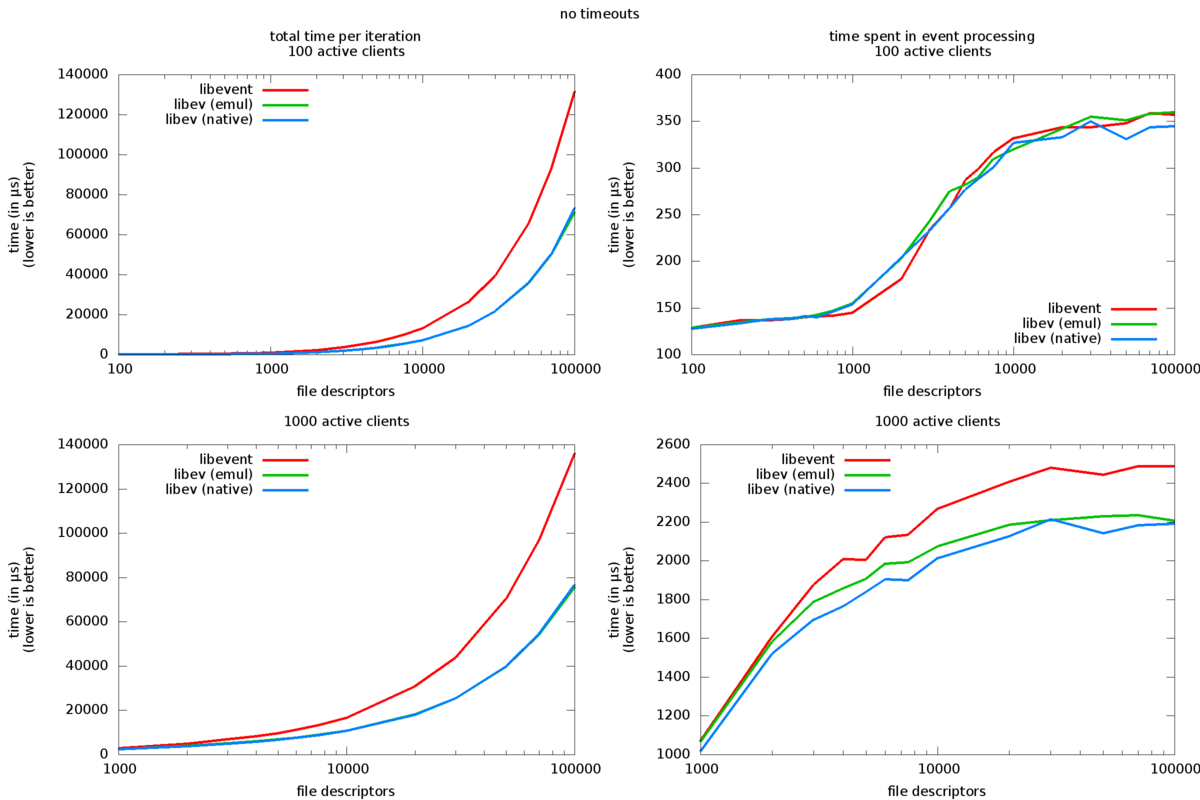
左边两个图显示了设置观察者、准备套接字和轮询事件所花费的总时间,而右边两个图仅包括实际的轮询处理。顶行代表 100 个活动客户端(执行 I/O 的客户端),底行使用 1000 个。所有图形都有一个对数 fd 轴,以合理地显示 100 到 100000 的大范围文件描述符编号(实际上,它的实际套接字对,因此实际上进程中的文件描述符数量是原来的两倍)。
讨论
与 libev 相比,libevent 每次迭代的总时间增加得快得多,无论客户端数量如何,花费的时间几乎是 libev 的两倍。不过,两者都表现出相似的增长特征。
轮询时间也非常相似,libevent 在 1000-fd 情况下始终较慢,而在 100-fd 情况下,时间几乎相同。然而,绝对差异很小(小于 5%)。
本机 API 时序始终优于仿真 API,但绝对差异也很小。
解释
libevent 设置或更改事件观察器的成本显然比 libev 高得多,API 差异无法解释这一点(libev 中的原生 API 和仿真 API 之间的差异非常小)。这在实践中很重要,因为 libevent API 没有很好的接口来动态更改事件观察者或超时。
在文件描述符数量较多时,libev 始终比 libevent 快。
此外,在这种情况下,libevent API 模拟本身只会导致很小的开销。
第二个基准:空闲超时,100 和 1000 个活动客户端
再次,先看结果:
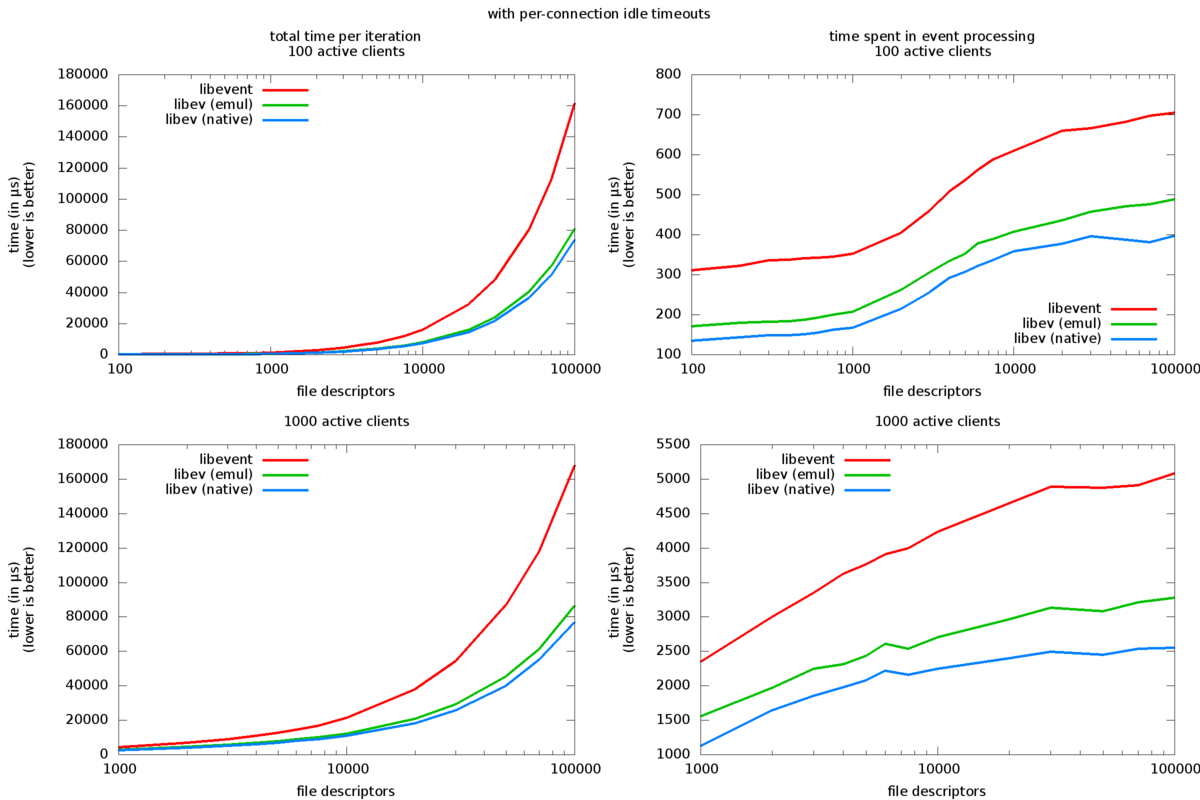
图形布局与第一个基准测试相同。不同的是,这一次,每个套接字都有一个随机超时。这样做是为了反映网络服务器通常需要维护每个连接的空闲超时的现实条件。这些空闲超时将在活动中重置。这是通过在设置期间设置随机 10 到 11 秒超时来实现的,并在每次客户端接收数据时删除/重新添加事件观察器。
讨论
图表都发生了巨大变化。libevent 每次迭代的总时间显着增加,但 libev 曲线仅略微增加。原生 API 和模拟 API 之间的区别变得更加明显。
事件处理图现在看起来非常不同,libev 在整个文件描述符编号范围内始终保持更快(两倍到几乎三倍)。表现出的增长行为大致相似,但 libev 比 libevent 低得多。
仅就 libev 而言,原生 API 始终比模拟 API 快,并且与第一个基准测试相比差异很明显,但在轮询时间方面,与 libevent 和 libev 之间的差异相比仍然相对较小。然而,总时间几乎减少了一半。
解释
libev 和 libevent 都使用二进制堆进行计时器管理(libevent 的早期版本使用红黑树),这解释了类似的增长特征。显然,即使使用相同的 API 调用,libev 也比 libevent 更好地利用了二元堆(请注意,即将发布的 3.33 版本的 libev,未在此基准测试中使用,使用缓存对齐的 4 堆和基准测试始终比 3.31 快)。
性能更高的另一个原因,尤其是在设置阶段,可能是 libevent 在每次更改时调用 epoll_ctl 系统调用(每个 fd 两次,用于 del/add),而 libev 仅在下一次轮询(EPOLL_MOD)之前将更改发送到内核)。
在这种情况下,本机 API 的速度明显更快(几乎是整体速度的两倍)。最可能的原因还是定时器管理,因为 libevent 使用两个 O(log n) 操作,而 libev 需要一个更简单的 O(log n) 操作。
概括
基准测试清楚地表明,libev 的成本要低得多,因此比 libevent 更快。API 设计问题也在结果中发挥作用,因为在使用计时器时,本机 API 可以比模拟 API 做得更好。尽管这使 libev 处于劣势(仿真层必须模拟其原生 API 没有的 libevent 的某些方面。它还必须将每个 libevent 观察者映射到它自己的三个观察者,并且必须运行 thunking 代码以从中进行映射由于回调的结构不同,这三个观察者指向 libevent 用户代码)。即使使用 libevent 仿真 API,它仍然比 libevent 快得多。
附录:libev 4.03、libevent 1.4.13、libevent 2.0.10 的基准图
以下是基准图表,使用更多当前版本重做。没有什么太大的变化,libevent2 似乎慢了一点(可能是由于额外的线程锁定),libev 快了一点。
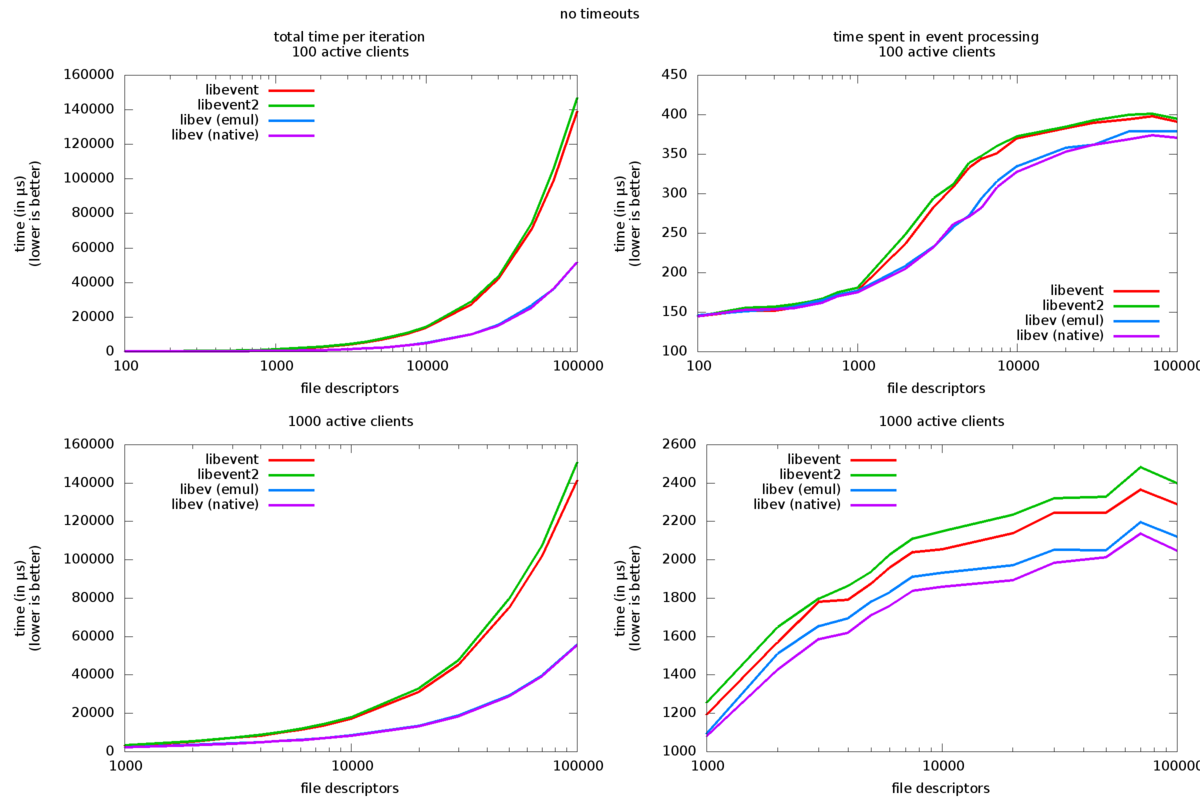
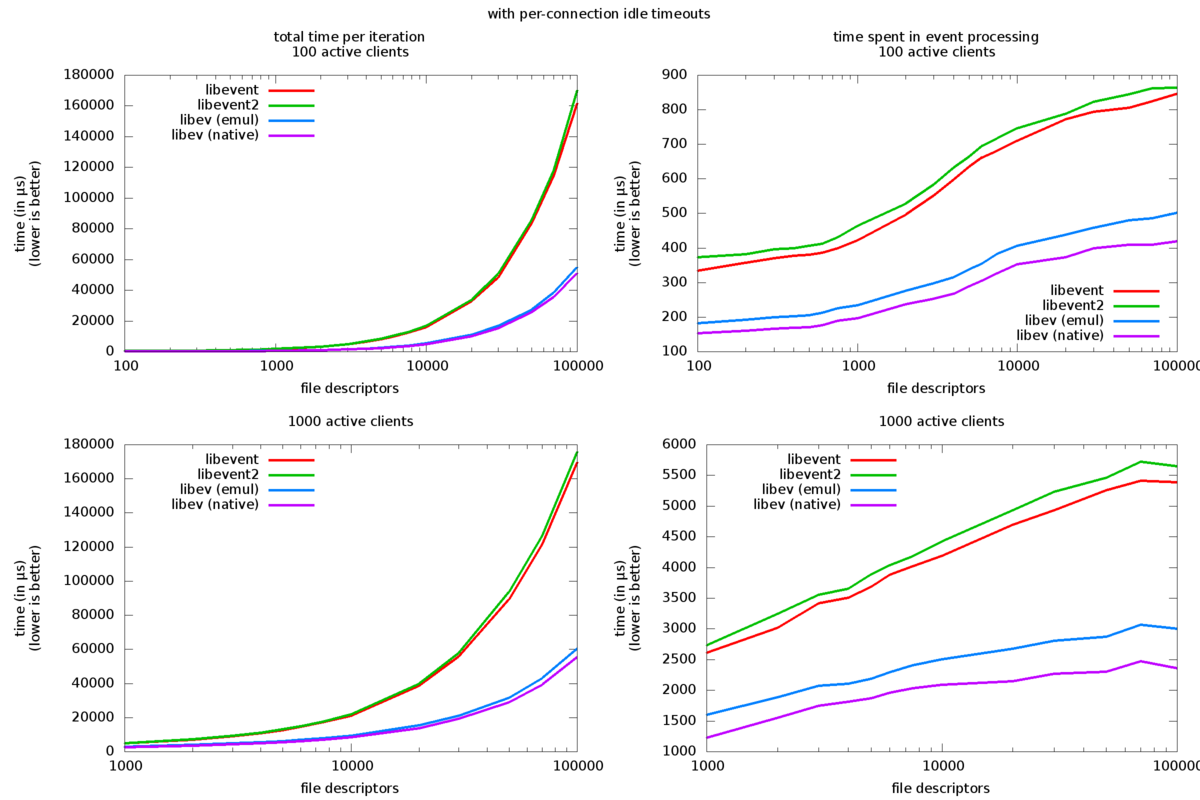
作者/联系人
马克·亚历山大·莱曼 <libev@schmorp.de>
2011 年 1 月 11 日,第 6 版
 评论加载中,请稍后...
评论加载中,请稍后...