TokuMX vs. MongoDB 性能对比
nosqldb.org
TokuDB 的ft tree 用在MongoDB产品TokuMX已经发布。MongoDB 在大量数据(比如1亿条记录)后,插入性能急剧下降。
Tokutek数据
带索引插入性能对比。
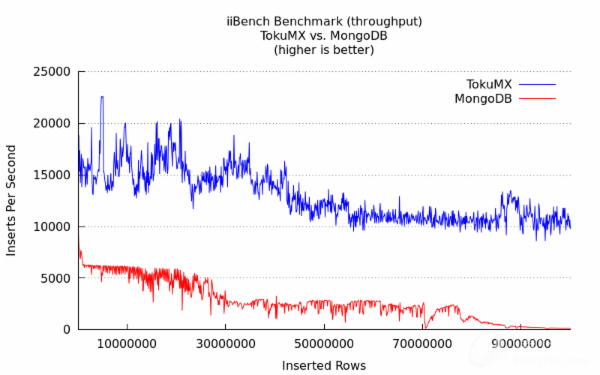
http://www.tokutek.com/2013/06/iibench-benchmark-tokumx-vs-mongodb/
以上为Tokutek的测试数据,下面为我测试的数据:
笔者实际测试
生产数据2亿多条导入测试
先建集合,创建3个索引,包括_id共4个索引。
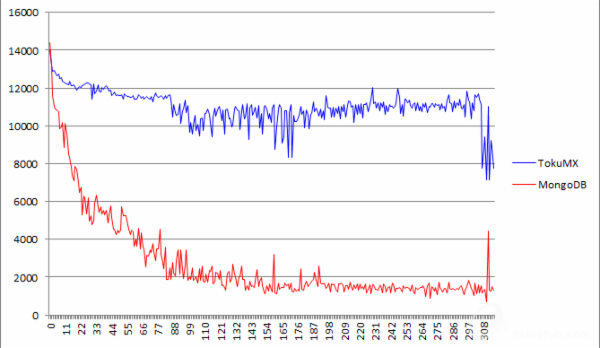
TokuMX 5个多小时导完数据,官方MongoDB 2.2.4版本竟然花了2天2夜多,近58个小时
使用mongostat统计,每分钟取值一个,纵坐标为inserts/s,横坐标为分钟。
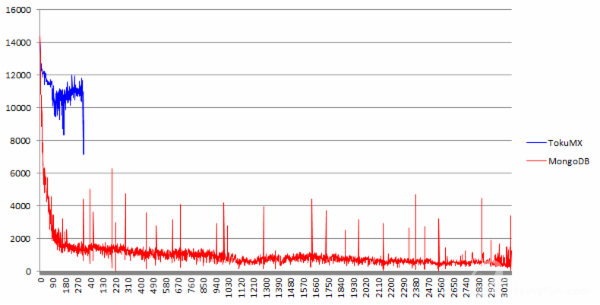
局部放大图:
磁盘空间占用比较:
TokuMX 18G,MongoDB 80G
内存使用比较:
TokuMX,cacheSize设置为30G,开directio,内存使用完没有cache的。
# free -g
total used free shared buffers cached
Mem: 31 31 0 0 0 0
-/+ buffers/cache: 30 0
Swap: 15 0 15
MongoDB,内存使用完,实际在cache里面
# free -g
total used free shared buffers cached
Mem: 31 31 0 0 0 28
-/+ buffers/cache: 1 29
Swap: 15 0 15
cpu使用:
未详细记录,TokuMX要高10%左右。
io:
MongoDB io要高不少。
总结:TokuMX太让人激动了,没有不使用它的理由,不过目前有些不支持的功能,如geo索引。
Currently unsupported functionality
● dropDups option for unique indexes
● Background Indexing, the “background” option is ignored when creating indexes.
● Fulltext indexes
● Geospatial indexes
磁盘消耗对比:
选择MongoDB就必然会面对磁盘消耗的问题。我们拿到的数据大概是这样的:每天的数据量不到200万条,平均数据的大小不超过4k,但MongoDB存一个月的数据就需要接近40G,最近三个月的数据则需要接近100G。限于原有硬件环境,只能保存最近三个月的数据,但业务又需要保存至少一年的数据,所以必须另想办法。
最终我们选定的方案是TokuMX。它是一款开源的、高性能的MongoDB发布(distribution),在提供与MongoDB完全兼容的客户端、API的同时,号称可以减少90%的存储空间,同时提供20倍的性能提升。我也了解到,已经有一些生产系统在使用TokuMX,反馈不错。
经过我的测试,用MongoDB需要102G的数据,采用默认的zlib压缩方式导入TokuMX之后,只有481MB,同时,导入速度大大提高(至少有10倍的提高),而查询性能没有降低。这个对比是我不敢想像的,直接解决了现在的问题。
对着这份数据,我不免好奇TokuMX究竟使用了怎样的技术?就我现在的了解,减少磁盘空间占用主要是在存储层使用了压缩方式(TokuMX宣称,如果不使用压缩,TokuMX的磁盘占用也比MongoDB少10%左右)。这种思路不稀奇,5.x版本的MySQL,如果设定file_format为Barracuda,也可以直接对表做压缩,同时不影响外部操作;提高写入速度则值得一提,原来TokuMX的做法是使用 分形树索引(Fractal Tree Index) ,替代了所谓“已经有40年历史的B树索引”。
所谓“分形”,大略来说,指的是“事物的每一部分都近似整体缩小后的形状”。TokuMX的分形树索引,严格说起来更像“B树 + 批量写入”的技巧,与B树的不同在于,分形树的每个内部节点都带有自己的缓冲区,它存储尚未落实(pending)到叶子节点的数据,默认情况下写入只会到缓冲区,缓冲区填满之后会把所有的写操作刷(flush)下去。
上一篇:一文了解大数据领域创业的机会与方向
下一篇:MongoDB与内存
 评论加载中,请稍后...
评论加载中,请稍后...