目录:
boost多索引容器multi_index_container详解
boost多索引容器multi_index_container架构图
boost多索引容器multi_index_container性能测试
原文地址:http://blog.csdn.net/gongxinheng/archive/2010/03/27/5421914.aspx
by: HengStar 2010/3/27
我是一名游戏开发程序员,研究C++ Boost库已经有一小段时日了,学的越多愈发愈感觉出它的强大,每次学习后在实战项目中高效地使用,都让我兴奋不已,为了让自己记忆更深刻,同时也希望越来越多的同行们能快速高质量地解决实际项目中遇到的各种问题,在此将我将自己实战中实用boost的经验分享给大家,本人才疏学浅,如果有什么问题希望读者们能帮助指出,大家共同探讨^_^
本章介绍的主题是multi_index_container
注:继续往下读之前希望你对C++模板和stl的一些知识有过了解
什么是多索引容器?为什么要使用它?如何使用?
接下来一一回答以上的问题。
想必大家在实际开发中一定多多少少会遇到以下的问题,我需要创建一个map,并且需要两种方式去索引,比如:创建一个<学号,姓名>的map,但是我既需要用学号去索引,又需要用姓名去索引,但std::map只能用它的key_type(在这里是学号)作为索引进行查找操作,该怎么办呢?“这有何难”?有人可能想到了,用value_type(姓名)索引也是可以的嘛,大不了写一个函数去遍历这个map,然后把要查找的姓名跟每个pair的second比较一下,如果相等不就找到了么?OK,没错,这样可以解决问题,但仅仅只是很粗糙地解决问题,如果这个map很大,每次查找都要遍历一遍,查找平均复杂度为O(n/2),如果你在需要高效的商业项目上使用,相信到性能测试的那天就是你收拾包袱走人的时刻了...just a joke^^让我们来讨论一些高效点的方法吧,仍然使用标准库的std::map,这次我们创建两个,一个使用<学号,姓名>,另一个则是<姓名,学号>,在每加入一个学生的时候都需要在两个map中各插入一个元素,移除的时候亦是,这种方法比最初的方法要好一些了,至少它可以做到高效的双向查找,但是仍然还是有缺陷的,比如说维护起来很麻烦,每次操作时都需要同时关照两个map的对应关系,一旦忽略了一些细节导致其中一个出了一点差错,可能就会酿成大错。
对于这种简单的需要双向查找的容器,使用boost::bimap就可以方便的解决问题,boost::bimap就是专为这种情况设计的容器,当然它的强大可能超出了你的想象,但是这里我们讨论的不是它,我们在实际开发中遇到的情况往往更复杂,比如说要创建一个<学号,学生信息>(学生信息是一个结构)的map,用前面的方法就得稍稍麻烦一点,比如重载学生信息结构的operator==来进行索引的依据,这些吃亏不讨好的方法我在这里就不再重复讨论了,让我们进入本章的正题,使用multi_index_container,没错,它可以轻松的帮你解决如上的所有问题,Let's go!
让我们先创建一些结构:
// 课程
struct Course
{
unsigned int course_num; // 课程编号
unsigned int course_hour; // 课时
std::string course_name; // 课程名
// 课程枚举
enum CourseNum_Enum
{
CourseNum_CPP = 0, // C++
CourseNum_English, // 英语
CourseNum_Maths, // 数学
CourseNum_Computer, // 计算机
CourseNum_DataStructure // 数据结构
};
static const Course courses[5];
Course( unsigned int num, unsigned int hour, std::string name );
};
// 学生
struct Student
{
unsigned int stu_num; // 学号
std::string stu_name; // 姓名
unsigned int stu_age; // 年龄
std::set<Course> stu_couselist; // 主修课程表
friend Student CreateStudent( const std::string& name, unsigned int age );
private:
Student( unsigned int num, const std::string& name, unsigned int age );
};
// 预定义一些课程
const Course Course::courses[5] = {
Course( CourseNum_CPP, 80, "C++程序设计" ),
Course( CourseNum_English, 60, "大学英语" ),
Course( CourseNum_Maths, 45, "离散数学" ),
Course( CourseNum_Computer, 50, "计算机组成原理" ),
Course( CourseNum_DataStructure, 60, "数据结构" )
};
以上的代码只是一些结构定义,比较简单,这里不再多介绍,唯一CreateStudent需要说明一下,由于学号是唯一不能重复的,所以创建学生时需要统一管理,构造函数声明为私有的是不让用户直接构造这个类,而只能通过CreateStudent函数去创建,这个CreateStudent函数就是一个简单的工厂生产函数,了解设计模式-工厂模式的读者一定很熟悉了,我们的目标是把学号、姓名、年龄同时作为索引,接下来引入我们的主角
#include "boost/multi_index_container.hpp"
#include "boost/multi_index/member.hpp"
#include "boost/multi_index/ordered_index.hpp"
using boost::multi_index_container;
using namespace boost::multi_index;
struct stu_num{}; // 索引-学号
struct stu_name{}; // 索引-姓名
struct stu_age{}; // 索引-年龄
typedef
boost::multi_index_container<
Student,
indexed_by<
ordered_unique<
// 学号是唯一值的索引
tag<stu_num>, BOOST_MULTI_INDEX_MEMBER(Student,unsigned int,stu_num)>,
// 姓名是非唯一值的索引
ordered_non_unique<
tag<stu_name>,BOOST_MULTI_INDEX_MEMBER(Student,std::string,stu_name)>,
// 年龄是非唯一值的索引
ordered_non_unique<
tag<stu_age>, BOOST_MULTI_INDEX_MEMBER(Student,unsigned int,stu_age)>
>
> StudentContainer;
解释一下上述代码,由于模板元是比较复杂的东东,要深入会更晕,这里只是简单介绍用法,所以不会剖析细节。首先是三个struct,这是给予需要创建索引的变量的标签(tag),为了一致性,我使用了跟Student结构成员一样的名字,接下来是最复杂的StudentContainer类型,对于C++模板不是很熟悉的人来说,如果此多的嵌套模板参数看起来是很容易晕的,所以写的时候一定得注意格式缩进,分解开来,首先类型是boost::multi_index_container模板的一个实例,两个模板参数,第一个是要创建索引针对的类型,这里是Student,第二个参数是索引的依据,用indexed_by模板来创建我们需要的索引键,前面创建的三个标签就在这里用上了,第一个索引是“学号”,由于学号是必须唯一不能重复的,这里我们用ordered_unique表示创建值唯一的有序索引,用tag模板实例化stu_num类型的标签,BOOST_MULTI_INDEX_MEMBER是一个宏,用于把类或结构的成员变量提取作为索引,而这个提取出来的东东就作为前面tag标签对应的索引值了,该宏接受三个参数,第一个参数是类或结构的名字,第二个参数是提取的成员变量的类型,第三个参数是成员变量名(注意:这里的stu_num是指Student::stu_num而前面tag中的stu_num是struct stu_num),然后再创建两个非唯一值的有序索引,用ordered_non_unique模板创建,参数和ordered_unique完全一致,这里就不重复了,OK,我们自己的多索引容器类型创建完了,接下来该使用了,我们还需要一个辅助函数来按我们传入的索引类型遍历输出容器的内容,
// PS:此函数引用自boost文档
template<typename Tag,typename MultiIndexContainer>
void print_out_by( const MultiIndexContainer& s )
{
/* obtain a reference to the index tagged by Tag */
const typename boost::multi_index::index<MultiIndexContainer,Tag>::type& i = get<Tag>(s);
typedef typename MultiIndexContainer::value_type value_type;
/* dump the elements of the index to cout */
std::copy(i.begin(),i.end(),std::ostream_iterator<value_type>(std::cout));
}
此函数也是一个模板函数,其中Tag参数代表了我们需要使用的索引标签,在我们的例子里可以是stu_num,stu_name或stu_age,模板参数MultiIndexContainer是一个boost::multi_index_container本例中可以用到的是StudentContainer,然后是const typename boost::multi_index::index<MultiIndexContainer,Tag>::type& i = get<Tag>(s);这段代码定义了一个容器索引,从容器s中提取出Tag标签作为索引的序列i(对于有序的容器也可以说是用Tag排序的序列),接下来是typedef typename MultiIndexContainer::value_type value_type;语句定义了容器的元素类型为value_type(如果传递StudentContainer作为MultiIndexContainer参数的实参,那么这里value_type就是Student),最后一句std::copy(i.begin(),i.end(),std::ostream_iterator<value_type>(std::cout));是将取出的序列i迭代输出到cout标准输出流中,当然这里的value_type要支持operator<<(也就是我们还需要给Student定义一个operator<<操作符的重载,别急,在接下来的文章中会依次给出源代码)。有了这个函数,我们就可以按任意索引的序列去输出了,举个简单的例子,在本例中我们可以用
print_out_by<stu_num>(studentsets); //studentsets是StudentContainer的实例
来按stu_num作为索引(或排序)依据来遍历输出所有Student的信息。
OK,就是这么简单,接下来我们就来看看实际应用的效果吧,让我们先创建一些学生的实体并加入到容器中去。
StudentContainer studentsets;
// 插入一些数据
Student& stu1 = CreateStudent( "张三", 19 );
stu1.stu_couselist.insert( Course::courses[Course::CourseNum_CPP] );
stu1.stu_couselist.insert( Course::courses[Course::CourseNum_English] );
studentsets.insert(stu1);
Student& stu2 = CreateStudent("李四", 18);
stu2.stu_couselist.insert( Course::courses[Course::CourseNum_CPP] );
stu2.stu_couselist.insert( Course::courses[Course::CourseNum_DataStructure] );
stu2.stu_couselist.insert( Course::courses[Course::CourseNum_Computer] );
studentsets.insert(stu2);
Student& stu3 = CreateStudent("王五", 21);
stu3.stu_couselist.insert( Course::courses[Course::CourseNum_English] );
stu3.stu_couselist.insert( Course::courses[Course::CourseNum_Maths] );
studentsets.insert(stu3);
Student& stu4 = CreateStudent("张三", 18);
stu4.stu_couselist.insert( Course::courses[Course::CourseNum_Computer] );
stu4.stu_couselist.insert( Course::courses[Course::CourseNum_Maths] );
studentsets.insert(stu4);
// 按学号排序输出序列
print_out_by<stu_num>(studentsets);
输出结果是按学号排序的,这里就不给出了,有兴趣的读者可以自己去试试,接下来我们要完成一些新的任务,呃...该做点什么好呢,好吧~让我们用stu_name(姓名)作为索引来查找姓名为“李四”的学生信息,代码如下:
// 用名字作为索引
StudentContainer::index<stu_name>::type& indexOfName = studentsets.get<stu_name>();
// 查找名叫李四的人
StudentContainer::index<stu_name>::type::iterator it = indexOfName.find("李四");
// 找到了?
if( it != indexOfName.end() )
{
// it就是一个Student序列的迭代器,现在你可以
// 像普通迭代器一样操作它了,比如cout << *it
}
看,是不是很简单呢?注意:这里我们用到的get是multi_index的成员函数,作为练习你还可以一下用stu_age作为索引进行查找,细心的读者可能注意到了,这个学生表里面可是有两个叫“张三”的,但这里的it只能找到其中一个,如果我要通过姓名找所有叫“张三”的学生信息怎么办呢?很好,这是一个比较麻烦的问题,但是不用质疑boost的强大,它能帮你解决所有的问题(至少是比较常见的问题),来看下面的代码
// 用名字作为索引
StudentContainer::index<stu_name>::type& indexOfName = studentsets.get<stu_name>();
// 查找名叫张三的人的下界
StudentContainer::index<stu_name>::type::iterator itL = indexOfName.lower_bound("张三");
// 查找名叫张三的人的上界
StudentContainer::index<stu_name>::type::iterator itU = indexOfName.upper_bound("张三");
// 遍历输出所有名叫“张三”的学生信息
while(itL != itU)
{
std::cout << *itL;
++itL;
}
stu_name是不唯一的(non_unique)索引,所以会有多个相同值是很正常的,这里的原理很简单,如果你用过std::multimap,上面的代码就不言而喻了,lower_bound取到的是第一个查找值所在的索引迭代器,如果没有找到就是end(),upper_bound返回的是查找值所在的索引迭代器的后一个位置,stl中有很多相似的用例我就不多解释了。怎么样,是不是稍稍比前面的用法难了一点点呢,嘿嘿,仅仅只是一点点哦~还是很值得用它的^^
本来的最后部分,我来为大家介绍如何去修改多索引容器中元素的修改。
熟悉有序容器的读者应该清楚:修改一个有序容器(比如map)中某元素的key值会怎么样呢?答案很明显,后果很严重...最起码的,有序容器很可能就变得无序了,这就是为什么boost的multi_index提供了replace和modify(这俩函数是ordered_index索引器提供的)成员函数来修改元素的内容,因为有序索引器一定要保证索引序列中的内容是有序的才能用高效的办法索引到需要的内容,replace方法提供所有迭代器与引用的有效性的保证,它返回一个bool值,没错,它会失败,什么情况下会失败呢?让我们看看如下代码
// 用名字作为索引
StudentContainer::index<stu_name>::type& indexOfName = studentsets.get<stu_name>();
// 查找名叫李四的人
StudentContainer::index<stu_name>::type::iterator it = indexOfName.find("李四");
// 找到了?
if( it != indexOfName.end() )
{
// 修改部分带索引的资料
Student stuTemp = *it;
// 没问题可以修改,age是不唯一的索引
stuTemp.stu_age = 20;
// 天哪,竟然要修改学号?
stuTemp.stu_num = 1;
// 将it指向的元素替换为stuTemp,ret为false
bool ret = indexOfName.replace( it, stuTemp );
}
上面的替换操作竟然失败了?为什么呢...答案很简单,stu_num被作为容器的唯一值索引(unique),那么你就等于已经保证了该值不会重复,当然你可以修改成一个不和其它元素产生冲突的值,但是stu_num为1的值已经存在了,所以replace失败了,结果呢,由于replace方法的保证,所以容器不会发生任何变化,所以,修改唯一值索引时一定要谨慎了。另外modify方法就没那么严格了,为什么要有两种修改函数的存在呢?答案是:效率,因为replace会发生两次赋值拷贝,如果结构很大并且使用的很频繁,有可能会成为性能瓶颈,modify的存在就是出于这种情况的考虑,modify方法有接受两个参数和三个参数的重载,先说说两个参数的用例吧,还是用上面的代码作为示例,我们修改一下找到以后的代码
// 修改部分带索引的资料
Student stuTemp = *it;
stuTemp.stu_age = 20;
stuTemp.stu_num = 1; // 改了这个后会导致replace失败
// 修改年龄为21,此句如果冲突,会删除相应的条目
bool ret = indexOfName.modify( it, CModifyStudentAge(21) );
同样,modify方法也具有bool返回值来告知是否成功,但是与replace不同的是,modify失败后会删除相应的条目(比较暴力-.-)...参数1和replace一样,参数2是一个函数对象,它接受一个容器元素类型作为参数,在这里,根据命名的意义,我是这样定义的
// 修改学生年龄的函数对象
class CModifyStudentAge
{
public:
CModifyStudentAge(unsigned int age) : m_age(age){}
void operator()(Student& stu)
{
// 修改年龄
stu.stu_age = m_age;
}
private:
unsigned int m_age;
};
这里由于是用引用作为参数,很自然的就去掉了拷贝的操作,但是失败的代价也是比较惨重的,如果你希望修改产生冲突后条目不会被删除,而是自己去处理,可以考虑用modify三个参数的重载,该方法接受一个额外的函数对象作为失败后的回调函数(Rollback),正所谓“亡羊补牢,为时未晚”,你可以在修改前先保存旧值,然后把旧值作为这个回调函数的参数去“补救”,这里不再给出具体例子了,boost文档中有详尽的用例。
有人可能已经注意到了,每次我找到相应的元素后我会先做一份拷贝,Student stuTemp = *it;为什么不通过it直接修改而非得费这劲呢?这是因为这是个const_iterator,可是我明明声明的是iterator类型啊,其实答案也能在文章中找到一些提示了,因为有序容器中的元素键值是不允许被随意修改,直接用iterator是很危险的,所以提供了replace和modify成员函数,但是我们自己清楚哪些成员是可以安全修改的,哪些成员是不能随便修改的,这样限制可能会影响一些效率,如果你觉得用modify比较麻烦,你也可以直接修改iterator指向的元素,看如下代码:
Student& stu = const_cast<Student&>(*it);
stu.stu_couselist.insert( Course::courses[Course::CourseNum_Maths] );
通过const_cast去掉了it的const性质,可以直接修改it了,但是如果你这样做了,你就必须为你接下来的行为负责任了,因为此时你的修改行为就不为容器索引器管理了,要切记...
好了,本章的介绍就到此结束了,因为只是简单的讲解多索引容器的用法,所以绕过了一些细节的部分,当然,multi_index_container的强大远远不仅如此,另外还有多种其它类型的索引器,例如hashed_unique,sequenced,random_access,可以根据实际需要选用合适的,具体请参见boost文档
最后,给出一些文章中用到的源码没有的实现部分
#include <algorithm>
#include <vector>
#include "boost/lambda/lambda.hpp"
#include "boost/function.hpp"
Course::Course( unsigned int num, unsigned int hour, std::string name ) :
course_num(num),
course_hour(hour),
course_name(name)
{
}
Student::Student( unsigned int num, const std::string& name, unsigned int age ) :
stu_num(num),
stu_name(name),
stu_age(age)
{
}
Student CreateStudent( const std::string& name, unsigned int age )
{
static unsigned int currentnum = 1; // 当前使用的学号
return Student( currentnum++, name, age );
}
std::ostream& operator<<( std::ostream& os, const Course& cou )
{
os << "课程编号:" << cou.course_num << "/t课程名" << cou.course_name << "/t课时:" << cou.course_hour << "/n";
return os;
}
std::ostream& operator<<( std::ostream& os, const Student& stu )
{
os << "学号:" << stu.stu_num << "/t姓名:" << stu.stu_name << "/t年龄" << stu.stu_age << "/n";
os << "主修课程:/n";
// 遍历并输出课程列表,使用lambda表达式,如不熟悉lambda表达式,请参考boost的lambda库相关资料
std::for_each( stu.stu_couselist.begin(), stu.stu_couselist.end(), std::cout << boost::lambda::_1 );
return os;
}
bool operator<( const Course& lhs, const Course& rhs )
{
return lhs.course_num < rhs.course_num;
}
by: HengStar 2010/3/27
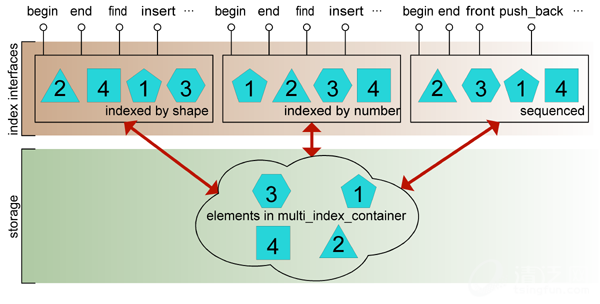
架构图:
multi_index_container性能测试
来源于libGod官网http://www.libgod.com/
boost中有个multi_index_container,感觉比较好用,但不知道性能怎么样。今天特意测试了下他的插入,查找,删除的性能。
测试代码:
#include <cstdio>
#include <map>
#include <vector>
#include <string>
#include <sstream>
#include <boost/multi_index_container.hpp>
#include <boost/multi_index/mem_fun.hpp>
#include <boost/multi_index/member.hpp>
#include <boost/multi_index/ordered_index.hpp>
#include <boost/smart_ptr.hpp>
#include "god/types.h"
#include "god/util.h"
#include "god/performance_counter.h"
using namespace std;
using namespace G;
struct Person {
typedef boost::shared_ptr<Person> ptr;
Person(int _id, std::string _name)
: id(_id)
, name(_name)
{}
int id;
std::string name;
};
struct id_tag{};
struct name_tag{};
typedef boost::multi_index_container<
Person::ptr,
boost::multi_index::indexed_by<
boost::multi_index::ordered_unique<
boost::multi_index::tag<id_tag>,
boost::multi_index::member<Person, int, &Person::id>
>,
boost::multi_index::ordered_unique<
boost::multi_index::tag<name_tag>,
boost::multi_index::member<Person, std::string, &Person::name>
>
>
> PersonContainer;
typedef PersonContainer::index<id_tag>::type IdIndex;
typedef PersonContainer::index<name_tag>::type NameIndex;
typedef std::map<int, Person::ptr> IdPersons;
typedef std::map<std::string, Person::ptr> NamePersons;
typedef std::vector<Person::ptr> Persons;
int main(int argc, char *argv[]) {
if (argc != 2) {
printf("Usage: program count\n");
return 0;
}
PersonContainer container;
IdPersons idPersons;
NamePersons namePersons;
printf("container: %d idPersons: %d namePersons: %d\n", sizeof(container), sizeof(idPersons), sizeof(namePersons));
Persons persons;
stringstream ss;
int id;
std::vector<char> flags;
int num = atoi(argv[1]);
int max = 10 * num;
flags.resize(max, 0);
for (int i = 0; i < num; ++i) {
do {
id = randInt(0, max);
} while (flags[id] == 1);
flags[id] = 1;
ss.str("helloworld");
ss << id;
persons.push_back(Person::ptr(new Person(id, ss.str())));
}
printf("---------------插入%d次-----------------\n", persons.size());
{
TIME_COUNTER_DEFAULT("Container插入");
for (Persons::iterator it = persons.begin(); it != persons.end(); ++it) {
container.insert(*it);
}
}
{
TIME_COUNTER_DEFAULT("Map插入");
for (Persons::iterator it = persons.begin(); it != persons.end(); ++it) {
idPersons.insert(IdPersons::value_type((*it)->id, *it));
namePersons.insert(NamePersons::value_type((*it)->name, *it));
}
}
printf("---------------查找%d次-----------------\n", persons.size());
{
TIME_COUNTER_DEFAULT("Container查找");
IdIndex &idIndex = container.get<id_tag>();
NameIndex &nameIndex = container.get<name_tag>();
for (Persons::iterator it = persons.begin(); it != persons.end(); ++it) {
idIndex.find((*it)->id);
nameIndex.find((*it)->name);
}
}
{
TIME_COUNTER_DEFAULT("Map查找");
for (Persons::iterator it = persons.begin(); it != persons.end(); ++it) {
idPersons.find((*it)->id);
namePersons.find((*it)->name);
}
}
printf("---------------删除%d次-----------------\n", persons.size());
{
TIME_COUNTER_DEFAULT("Container删除");
IdIndex &idIndex = container.get<id_tag>();
for (Persons::iterator it = persons.begin(); it != persons.end(); ++it) {
idIndex.erase(idIndex.find((*it)->id));
}
}
{
TIME_COUNTER_DEFAULT("Map删除");
for (Persons::iterator it = persons.begin(); it != persons.end(); ++it) {
idPersons.erase(idPersons.find((*it)->id));
namePersons.erase(namePersons.find((*it)->name));
}
}
return 0;
}
结果:
./godmulti_index_container.exe 100000
container: 16 idPersons: 24 namePersons: 24
---------------插入100000次-----------------
2013-Jun-07 03:14:04.094847 INFO g:performance god/multi_index_container.cpp:85 main
RealTime: 0.347873s
Desc: Container插入
2013-Jun-07 03:14:04.353037 INFO g:performance god/multi_index_container.cpp:91 main
RealTime: 0.257946s
Desc: Map插入
---------------查找100000次-----------------
2013-Jun-07 03:14:04.635155 INFO g:performance god/multi_index_container.cpp:99 main
RealTime: 0.282012s
Desc: Container查找
2013-Jun-07 03:14:04.860851 INFO g:performance god/multi_index_container.cpp:108 main
RealTime: 0.225587s
Desc: Map查找
---------------删除100000次-----------------
2013-Jun-07 03:14:05.083199 INFO g:performance god/multi_index_container.cpp:116 main
RealTime: 0.221576s
Desc: Container删除
2013-Jun-07 03:14:05.335577 INFO g:performance god/multi_index_container.cpp:123 main
RealTime: 0.251333s
Desc: Map删除
./godmulti_index_container.exe 5000000
container: 16 idPersons: 24 namePersons: 24
---------------插入5000000次-----------------
2013-Jun-07 03:41:53.712893 INFO g:performance god/multi_index_container.cpp:85 main
RealTime: 31.0026s
Desc: Container插入
2013-Jun-07 03:42:23.353184 INFO g:performance god/multi_index_container.cpp:91 main
RealTime: 29.6398s
Desc: Map插入
---------------查找5000000次-----------------
2013-Jun-07 03:42:51.957578 INFO g:performance god/multi_index_container.cpp:99 main
RealTime: 28.6033s
Desc: Container查找
2013-Jun-07 03:43:20.793262 INFO g:performance god/multi_index_container.cpp:108 main
RealTime: 28.8355s
Desc: Map查找
---------------删除5000000次-----------------
2013-Jun-07 03:43:39.491708 INFO g:performance god/multi_index_container.cpp:116 main
RealTime: 18.6607s
Desc: Container删除
2013-Jun-07 03:44:10.976808 INFO g:performance god/multi_index_container.cpp:123 main
RealTime: 31.4334s
Desc: Map删除
 评论加载中,请稍后...
评论加载中,请稍后...