构建高并发高可用的电商平台架构实践
一个非常的重要功能,主要有搜索词类目导航、自动提示和搜索排序功能。
开源的企业级搜索引擎主要有lucene, sphinx,这里不去论述哪种搜索引擎更好一些,不过选择搜索引擎除了基本的功能需要支持外,非功能方面需要考虑以下两点:
a、 搜索引擎是否支持分布式的索引和搜索,来应对海量的数据,支持读写分离,提高可用性
b、 索引的实时性
c、 性能
Solr是基于lucene的高性能的全文搜索服务器,提供了比lucene更为丰富的查询语言,可配置可扩展,对外提供基于http协议的XML/JSON格式的接口。
从Solr4版本开始提供了SolrCloud方式来支持分布式的索引,自动进行sharding数据切分;通过每个sharding的master-slave(leader、replica)模式提高搜索的性能;利用zookeeper对集群进行管理,包括leader选举等等,保障集群的可用性。
Lucene索引的Reader是基于索引的snapshot的,所以必须在索引commit的后,重新打开一个新的snapshot,才能搜索到新添加的内容;而索引的commit是非常耗性能的,这样达到实时索引搜索效率就比较低下。
对于索引搜索实时性,Solr4的之前解决方案是结合文件全量索引和内存增量索引合并的方式,参见下图。
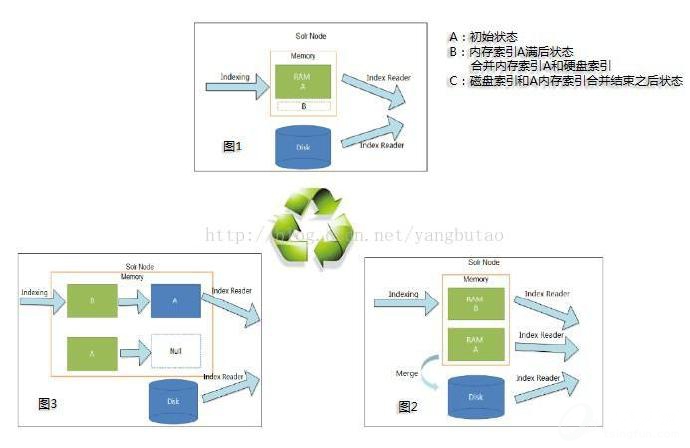
Solr4提供了NRT softcommit的解决方案,softcommit无需进行提交索引操作,就可以搜素到最新对索引的变更,不过对索引的变更并没有sync commit到硬盘存储上,若发生意外导致程序非正常结束,未commit的数据会丢失,因此需要定时的进行commit操作。
平台中对数据的索引和存储操作是异步的,可以大大提高可用性和吞吐量;只对某些属性字段做索引操作,存储数据的标识key,减少索引的大小;数据是存储在分布式存储HBase 中的,HBase对二级索引搜索支持的不好,然而可以结合Solr搜索功能进行多维度的检索统计。
索引数据和HBase数据存储的一致性,也就是如何保障HBase存储的数据都被索引过,可以采用confirm确认机制,通过在索引前建立待索引数据队列,在数据存储并索引完成后,从待索引数据队列中删除数据。
7) 日志收集
在整个交易过程中,会产生大量的日志,这些日志需要收集到分布式存储系统中存储起来,以便于集中式的查询和分析处理。
日志系统需具备三个基本组件,分别为agent(封装数据源,将数据源中的数据发送给collector),collector(接收多个agent的数据,并进行汇总后导入后端的store中),store(中央存储系统,应该具有可扩展性和可靠性,应该支持当前非常流行的HDFS)。
开源的日志收集系统业界使用的比较多的是cloudera的Flume和facebook的Scribe,其中Flume目前的版本FlumeNG对Flume从架构上做了较大的改动。
在设计或者对日志收集系统做技术选型时,通常需要具有以下特征:
a、 应用系统和分析系统之间的桥梁,将他们之间的关系解耦
b、 分布式可扩展,具有高的扩展性,当数据量增加时,可以通过增加节点水平扩展
日志收集系统是可以伸缩的,在系统的各个层次都可伸缩,对数据的处理不需要带状态,伸缩性方面也比较容易实现。
c、 近实时性
在一些时效性要求比较高的场景中,需要可以及时的收集日志,进行数据分析;
一般的日志文件都会定时或者定量的进行rolling,所以实时检测日志文件的生成,及时对日志文件进行类似的tail操作,并支持批量发送提高传输效率;批量发送的时机需要满足消息数量和时间间隔的要求。
d、 容错性
Scribe在容错方面的考虑是,当后端的存储系统crash时,scribe会将数据写到本地磁盘上,当存储系统恢复正常后,scribe将日志重新加载到存储系统中。
FlumeNG通过Sink Processor实现负载均衡和故障转移。多个Sink可以构成一个Sink Group。一个Sink Processor负责从一个指定的Sink Group中激活一个Sink。Sink Processor可以通过组中所有Sink实现负载均衡;也可以在一个Sink失败时转移到另一个。
e、 事务支持
Scribe没有考虑事务的支持。
Flume通过应答确认机制实现事务的支持,参见下图,
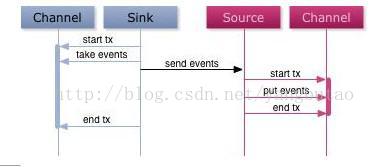
通常提取发送消息都是批量操作的,消息的确认是对一批数据的确认,这样可以大大提高数据发送的效率。
f、 可恢复性
FlumeNG的channel根据可靠性的要求的不同,可以基于内存和文件持久化机制,基于内存的数据传输的销量比较高,但是在节点宕机后,数据丢失,不可恢复;而文件持久化宕机是可以恢复的。
g、 数据的定时定量归档
数据经过日志收集系统归集后,一般存储在分布式文件系统如Hadoop,为了便于对数据进行后续的处理分析,需要定时(TimeTrigger)或者定量(SizeTrigger的rolling分布式系统的文件。
8) 数据同步
在交易系统中,通常需要进行异构数据源的同步,通常有数据文件到关系型数据库,数据文件到分布式数据库,关系型数据库到分布式数据库等。数据在异构源之间的同步一般是基于性能和业务的需求,数据存储在本地文件中一般是基于性能的考虑,文件是顺序存储的,效率还是比较高的;数据同步到关系型数据一般是基于查询的需求;而分布式数据库是存储越来越多的海量数据的,而关系型数据库无法满足大数据量的存储和查询请求。
在数据同步的设计中需要综合考虑吞吐量、容错性、可靠性、一致性的问题
同步有实时增量数据同步和离线全量数据区分,下面从这两个维度来介绍一下,
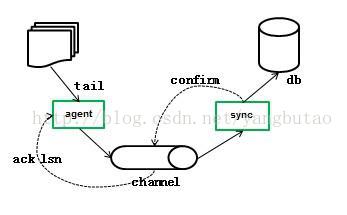
实时增量一般是Tail文件来实时跟踪文件变化,批量或者多线程往数据库导出,这种方式的架构类似于日志收集框架。这种方式需要有确认机制,包括两个方面。
一个方面是Channel需要给agent确认已经批量收到数据记录了,发送LSN号给agent,这样在agent失效恢复时,可以从这个LSN点开始tail;当然对于允许少量的重复记录的问题(发生在channel给agent确认的时,agent宕机并未受到确认消息),需要在业务场景中判断。
另外一个方面是sync给channel确认已经批量完成写入到数据库的操作,这样channel可以删除这部分已经confirm的消息。
基于可靠性的要求,channel可以采用文件持久化的方式。
参见下图
离线全量遵循空间间换取时间,分而治之的原则,尽量的缩短数据同步的时间,提高同步的效率。
需要对源数据比如mysql进行切分,多线程并发读源数据,多线程并发批量写入分布式数据库比如HBase,利用channel作为读写之间的缓冲,实现更好的解耦,channel可以基于文件存储或者内存。参见下图:
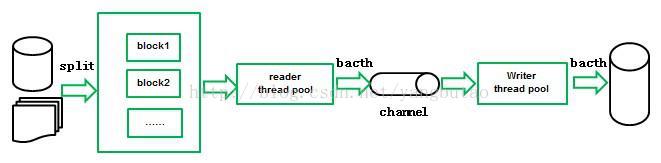
对于源数据的切分,如果是文件可以根据文件名称设置块大小来切分。
对于关系型数据库,由于一般的需求是只离线同步一段时间的数据(比如凌晨把当天的订单数据同步到HBase),所以需要在数据切分时(按照行数切分),会多线程扫描整个表(及时建索引,也要回表),对于表中包含大量的数据来讲,IO很高,效率非常低;这里解决的方法是对数据库按照时间字段(按照时间同步的)建立分区,每次按照分区进行导出。
9) 数据分析
从传统的基于关系型数据库并行处理集群、用于内存计算近实时的,到目前的基于hadoop的海量数据的分析,数据的分析在大型电子商务网站中应用非常广泛,包括流量统计、推荐引擎、趋势分析、用户行为分析、数据挖掘分类器、分布式索引等等。
并行处理集群有商业的EMC Greenplum,Greenplum的架构采用了MPP(大规模并行处理),基于postgresql的大数据量存储的分布式数据库。
内存计算方面有SAP的HANA,开源的nosql内存型的数据库mongodb也支持mapreduce进行数据的分析。
海量数据的离线分析目前互联网公司大量的使用Hadoop,Hadoop在可伸缩性、健壮性、计算性能和成本上具有无可替代的优势,事实上已成为当前互联网企业主流的大数据分析平台
Hadoop通过MapReuce的分布式处理框架,用于处理大规模的数据,伸缩性也非常好;但是MapReduce最大的不足是不能满足实时性的场景,主要用于离线的分析。
基于MapRduce模型编程做数据的分析,开发上效率不高,位于hadoop之上Hive的出现使得数据的分析可以类似编写sql的方式进行,sql经过语法分析、生成执行计划后最终生成MapReduce任务进行执行,这样大大提高了开发的效率,做到以ad-hoc(计算在query发生时)方式进行的分析。
基于MapReduce模型的分布式数据的分析都是离线的分析,执行上都是暴力扫描,无法利用类似索引的机制;开源的Cloudera Impala是基于MPP的并行编程模型的,底层是Hadoop存储的高性能的实时分析平台,可以大大降低数据分析的延迟。
目前Hadoop使用的版本是Hadoop1.0,一方面原有的MapReduce框架存在JobTracker单点的问题,另外一方面JobTracker在做资源管理的同时又做任务的调度工作,随着数据量的增大和Job任务的增多,明显存在可扩展性、内存消耗、线程模型、可靠性和性能上的缺陷瓶颈;Hadoop2.0 yarn对整个框架进行了重构,分离了资源管理和任务调度,从架构设计上解决了这个问题。
参考Yarn的架构
10) 实时计算
在互联网领域,实时计算被广泛实时监控分析、流控、风险控制等领域。电商平台系统或者应用对日常产生的大量日志和异常信息,需要经过实时过滤、分析,以判定是否需要预警;
上一篇:站长投放广告绝对不做的事:Google Adsense和百度联盟广告违规分析
下一篇:软件测试中的性能测试、负载测试、压力测试
 评论加载中,请稍后...
评论加载中,请稍后...