构建高并发高可用的电商平台架构实践
同时需要对系统做自我保护机制,比如对模块做流量的控制,以防止非预期的对系统压力过大而引起的系统瘫痪,流量过大时,可以采取拒绝或者引流等机制;有些业务需要进行风险的控制,比如彩票中有些业务需要根据系统的实时销售情况进行限号与放号。
原始基于单节点的计算,随着系统信息量爆炸式产生以及计算的复杂度的增加,单个节点的计算已不能满足实时计算的要求,需要进行多节点的分布式的计算,分布式实时计算平台就出现了。
这里所说的实时计算,其实是流式计算,概念前身其实是CEP复杂事件处理,相关的开源产品如Esper,业界分布式的流计算产品Yahoo S4,Twitter storm等,以storm开源产品使用最为广泛。
对于实时计算平台,从架构设计上需要考虑以下几个因素:
1、 伸缩性
随着业务量的增加,计算量的增加,通过增加节点处理,就可以处理。
2、 高性能、低延迟
从数据流入计算平台数据,到计算输出结果,需要性能高效且低延迟,保证消息得到快速的处理,做到实时计算。
3、 可靠性
保证每个数据消息得到一次完整处理。
4、 容错性
系统可以自动管理节点的宕机失效,对应用来说,是透明的。
Twitter的Storm在以上这几个方面做的比较好,下面简介一下Storm的架构。
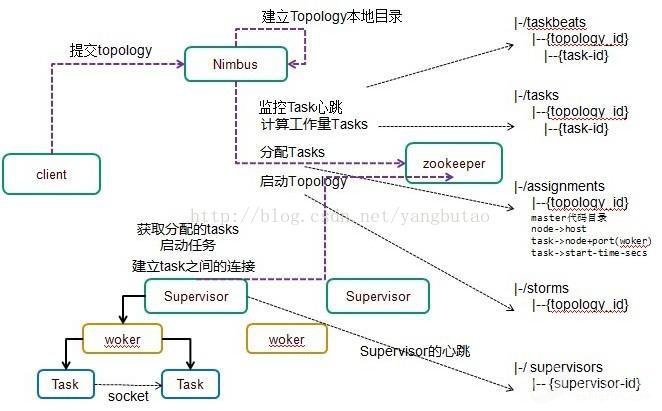
整个集群的管理是通过zookeeper来进行的。
客户端提交拓扑到nimbus。
Nimbus针对该拓扑建立本地的目录根据topology的配置计算task,分配task,在zookeeper上建立assignments节点存储task和supervisor机器节点中woker的对应关系。
在zookeeper上创建taskbeats节点来监控task的心跳;启动topology。
Supervisor去zookeeper上获取分配的tasks,启动多个woker进行,每个woker生成task,一个task一个线程;根据topology信息初始化建立task之间的连接;Task和Task之间是通过zeroMQ管理的;之后整个拓扑运行起来。
Tuple是流的基本处理单元,也就是一个消息,Tuple在task中流转,Tuple的发送和接收过程如下:
发送Tuple,Worker提供了一个transfer的功能,用于当前task把tuple发到到其他的task中。以目的taskid和tuple参数,序列化tuple数据并放到transfer queue中。
在0.8版本之前,这个queue是LinkedBlockingQueue,0.8之后是DisruptorQueue。
在0.8版本之后,每一个woker绑定一个inbound transfer queue和outbond queue,inbound queue用于接收message,outbond queue用于发送消息。
发送消息时,由单个线程从transferqueue中拉取数据,把这个tuple通过zeroMQ发送到其他的woker中。
接收Tuple,每个woker都会监听zeroMQ的tcp端口来接收消息,消息放到DisruptorQueue中后,后从queue中获取message(taskid,tuple),根据目的taskid,tuple的值路由到task中执行。每个tuple可以emit到direct steam中,也可以发送到regular stream中,在Reglular方式下,由Stream Group(stream id–>component id –>outbond tasks)功能完成当前tuple将要发送的Tuple的目的地。
通过以上分析可以看到,Storm在伸缩性、容错性、高性能方面的从架构设计的角度得以支撑;同时在可靠性方面,Storm的ack组件利用异或xor算法在不失性能的同时,保证每一个消息得到完整处理的同时。
11) 实时推送
实时推送的应用场景非常多,比如系统的监控动态的实时曲线绘制,手机消息的推送,web实时聊天等。
实时推送有很多技术可以实现,有Comet方式,有websocket方式等。
Comet基于服务器长连接的“服务器推”技术,包含两种:
Long Polling:服务器端在接到请求后挂起,有更新时返回连接即断掉,然后客户端再发起新的连接
Stream方式: 每次服务端数据传送不会关闭连接,连接只会在通信出现错误时,或是连接重建时关闭(一些防火墙常被设置为丢弃过长的连接, 服务器端可以设置一个超时时间, 超时后通知客户端重新建立连接,并关闭原来的连接)。
Websocket:长连接,全双工通信
是 Html5 的一种新的协议。它实现了浏览器与服务器的双向通讯。webSocket API 中,浏览器和服务器端只需要通过一个握手的动作,便能形成浏览器与客户端之间的快速双向通道,使得数据可以快速的双向传播。
Socket.io是一个NodeJS websocket库,包括客户端的JS和服务端的的nodejs,用于快速构建实时的web应用。
12) 推荐引擎
待补充
6. 数据存储
数据库存储大体分为以下几类,有关系型(事务型)的数据库,以oracle、mysql为代表,有keyvalue数据库,以redis和memcached db为代表,有文档型数据库如mongodb,有列式分布式数据库以HBase,cassandra,dynamo为代表,还有其他的图形数据库、对象数据 库、xml数据库等。每种类型的数据库应用的业务领域是不一样的,下面从内存型、关系型、分布式三个维度针对相关的产品做性能可用性等方面的考量分析。
1) 内存型数据库
内存型的数据库,以高并发高性能为目标,在事务性方面没那么严格,以开源nosql数据库mongodb、redis为例
Ø Mongodb
通信方式
多线程方式,主线程监听新的连接,连接后,启动新的线程做数据的操作(IO切换)。
数据结构
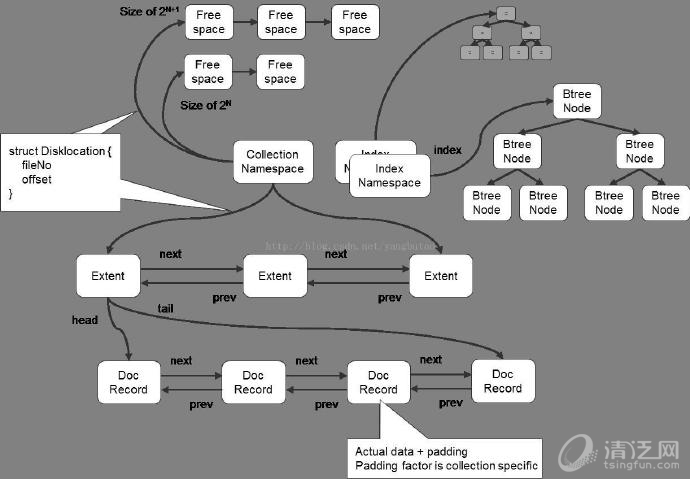
数据库–>collection–>record
MongoDB在数据存储上按命名空间来划分,一个collection是一个命名空间,一个索引也是一个命名空间。
同一个命名空间的数据被分成很多个Extent,Extent之间使用双向链表连接。
在每一个Extent中,保存了具体每一行的数据,这些数据也是通过双向链接连接的。
每一行数据存储空间不仅包括数据占用空间,还可能包含一部分附加空间,这使得在数据update变大后可以不移动位置。
索引以BTree结构实现。
如果你开启了jorunaling日志,那么还会有一些文件存储着你所有的操作记录。
持久化存储
MMap方式把文件地址映射到内存的地址空间,直接操作内存地址空间就可以操作文件,不用再调用write,read操作,性能比较高。
mongodb调用mmap把磁盘中的数据映射到内存中的,所以必须有一个机制时刻的刷数据到硬盘才能保证可靠性,多久刷一次是与syncdelay参数相关的。
journal(进行恢复用)是Mongodb中的redo log,而Oplog则是负责复制的binlog。如果打开journal,那么即使断电也只会丢失100ms的数据,这对大多数应用来说都可以容忍了。从1.9.2+,mongodb都会默认打开journal功能,以确保数据安全。而且journal的刷新时间是可以改变的,2-300ms的范围,使用 –journalCommitInterval 命令。Oplog和数据刷新到磁盘的时间是60s,对于复制来说,不用等到oplog刷新磁盘,在内存中就可以直接复制到Sencondary节点。
事务支持
Mongodb只支持对单行记录的原子操作
HA集群
用的比较多的是Replica Sets,采用选举算法,自动进行leader选举,在保证可用性的同时,可以做到强一致性要求。
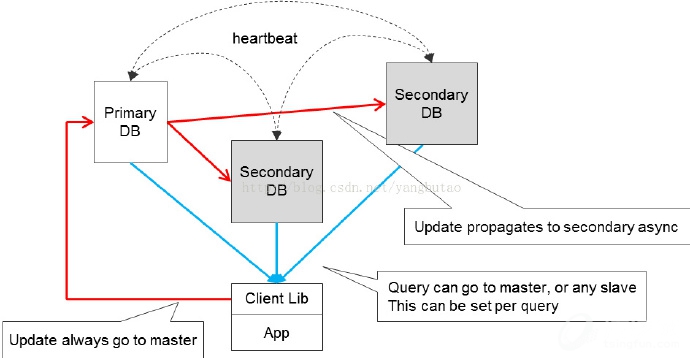
当然对于大量的数据,mongodb也提供了数据的切分架构Sharding。
Ø Redis
丰富的数据结构,高速的响应速度,内存操作
通信方式
因都在内存操作,所以逻辑的操作非常快,减少了CPU的切换开销,所以为单线程的模式(逻辑处理线程和主线程是一个)。
reactor模式,实现自己的多路复用NIO机制(epoll,select,kqueue等)
单线程处理多任务
数据结构
hash+bucket结构,当链表的长度过长时,会采取迁移的措施(扩展原来两倍的hash表,把数据迁移过去,expand+rehash)
持久化存储
a、全量持久化RDB(遍历redisDB,读取bucket中的key,value),save命令阻塞主线程,bgsave开启子进程进行snapshot持久化操作,生成rdb文件。
在shutdown时,会调用save操作
数据发生变化,在多少秒内触发一次bgsave
sync,master接受slave发出来的命令
b、增量持久化(aof类似redolog),先写到日志buffer,再flush到日志文件中(flush的策略可以配置的,而已单条,也可以批量),只有flush到文件上的,才真正返回客户端。
要定时对aof文件和rdb文件做合并操作(在快照过程中,变化的数据先写到aof buf中等子进程完成快照<内存snapshot>后,再进行合并aofbuf变化的部分以及全镜像数据)。
在高并发访问模式下,RDB模式使服务的性能指标出现明显的抖动,aof在性能开销上比RDB好,但是恢复时重新加载到内存的时间和数据量成正比。
集群HA
通用的解决方案是主从备份切换,采用HA软件,使得失效的主redis可以快速的切换到从redis上。主从数据的同步采用复制机制,该场景可以做读写分离。
目前在复制方面,存在的一个问题是在遇到网络不稳定的情况下,Slave和Master断开(包括闪断)会导致Master需要将内存中的数据全部重新生成rdb文件(快照文件),然后传输给Slave。Slave接收完Master传递过来的rdb文件以后会将自身的内存清空,把rdb文件重新加载到内存中。这种方式效率比较低下,在后面的未来版本Redis2.8作者已经实现了部分复制的功能。
2) 关系型数据库
关系型数据库在满足并发性能的同时,也需要满足事务性,以mysql数据库为例,讲述架构设计原理,在性能方面的考虑,以及如何满足可用性的需求。
Ø mysql的架构原理(innodb)
在架构上,mysql分为server层
上一篇:站长投放广告绝对不做的事:Google Adsense和百度联盟广告违规分析
下一篇:软件测试中的性能测试、负载测试、压力测试
 评论加载中,请稍后...
评论加载中,请稍后...